Beyond Jupyter Notebooks

Beyond jupyter notebooks
Jupyter Notebooks are widespread

Jupyter notebooks have become the de-facto standard for data scientists. They combine code, data, and visualization, and can be shared via e.g. github. Many companies, such as Netflix, Airbnb, Latchbio, use jupyter notebooks successfully to manage their complex data needs.
But they have some severe limitations
- They can often fail, for many reasons
- Common complaints: good for exploring, but when you need to do “real work” you go elsewhere
- Scaling or using different or multiple machines for heavy compute is not practical or impossible
- Sharing is usually limited to posting in github, no centralized search, difficult for teams to work together on a single notebook
- All code runs in a single kernel, tying all the code to a single instance. If you want to run someone else’s notebook, you have to use a specialized service with limitations and problems with data, or you need to manually install libraries, or run a docker container, and again, where to store the data outputs is left to you
Jupyter notebooks grew from solving a particular set of problems, and its growth is constrained by those technical origins.
Notebooks are tightly coupled systems: it’s all or nothing.
Jupyter Notebooks Reimagined
Imagine if you could
- write code in any language
- combine it seamlessly with browser interactive visualization (without complicated bridging code)
- share and publish instantly with your team or audience, and know that they will be able to instantly re-run the computation, if needed, without installation
- re-use any component that will reliable connect to your own workflow without complicated and time-consuming finessing
- run on any computer or cluster, and never have to perform complicated setups when running other workflows
That’s the metapage platform:
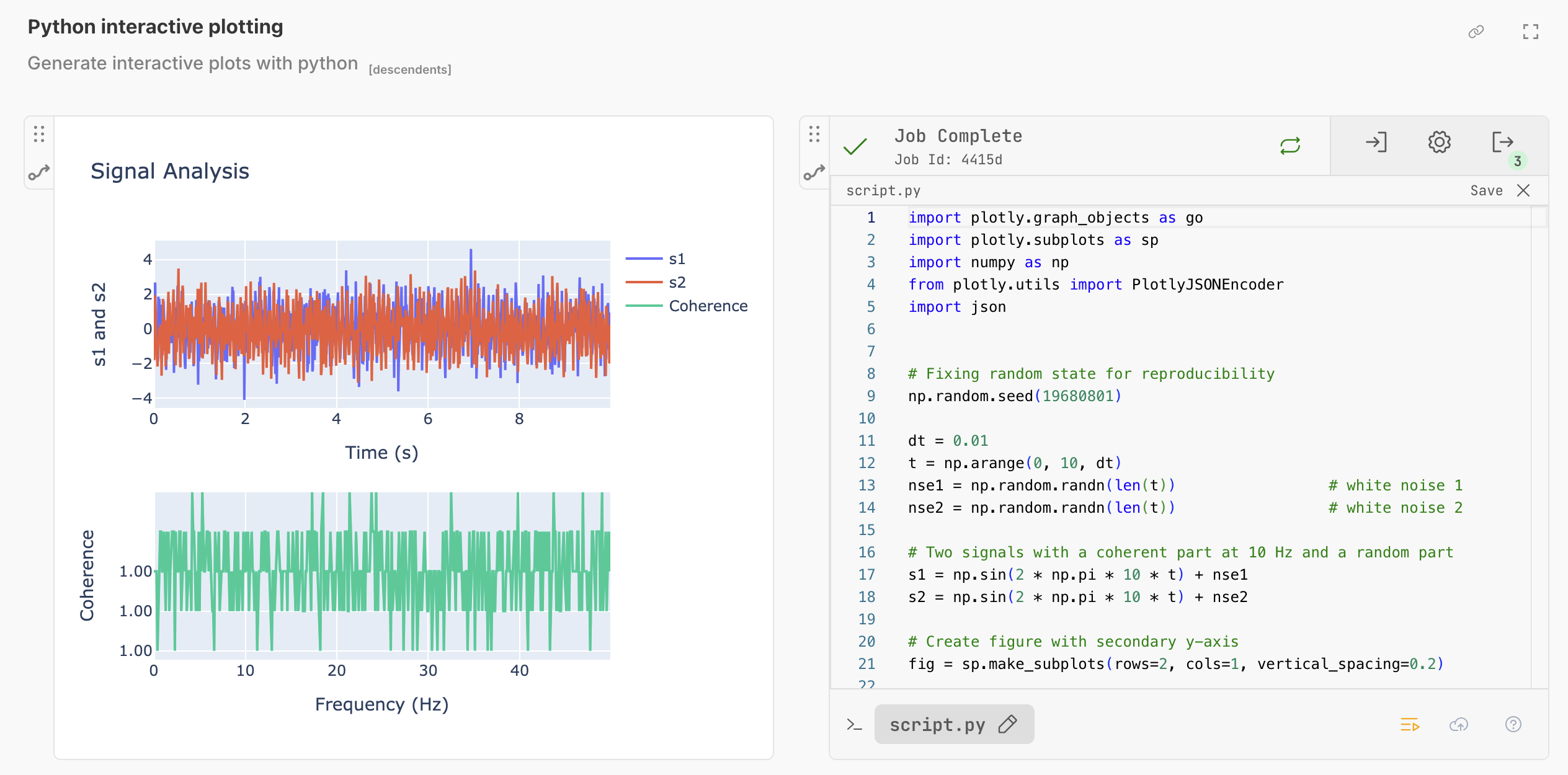
In the example workflow, you have python code generating a plotly diagram. Unlike a jupyter notebook, you can simply copy this immediately and start modifying code. There is no complex setup, and you can published in a single click.
Metapages are web-first workflows. They consist of components, that are also webpages. So a jupyter notebook consists of “cells” which are code blocks executing in the same “kernel” (computer process).
Metapage components, called meta_frames,_ are also websites. The parent page uses an open-source module to connect the frames via data pipes. Since the components are webpages, they can be anything.
For example, one component runs docker containers. A docker container can be represented as a URL, where the URL contains everything needed to defined a docker image, build the docker image, and run the container.
This way, components (jupyter’s cells) are completely independent of each other, and thus can be published independently, and immediately found and used by your audience.
They are a new way of doing data science, and we hope they will foster a new age of sharing, communication and collaboration, by removing the drudgery and making sharing code, data, and compute happen at the speed of thought.
Sharing
Sharing code and data is the lifeblood of (data) science. Jupyter notebooks do not address this need directly, instead, you can kindof share code by publishing the notebook in a fixed repository like github.
And there it becomes a static artifact. You cannot share back and forth easily, or share only parts, or share data with the notebook where the data is modified.
Metapages are web-first, shareable with a single click, and not only the pages, but the components also can be independently shared and published. You can then embed
| Jupyter Notebooks | Metapages | |
|---|---|---|
| Languages | Many, but only a single kernel per notebook | Any, each cell can potentially have their own container |
| Sharing | Limited to once | Immediate with one click, real-time, customizable |
| Data | Usually has to be mounted in from some defined remote storage, vendor lock-in limits data sharing, too many solutions prevent ease of sharing | All metapages come with a scoped file system, also can consume any cloud storage. Copying a metapage copies all data instantly. |
| Visualization | Complex bridge code, visualization libraries need to be installed on the browser, visualizations are not easily shared, they are tied to the notebook | Any visualization library can be added by any user, and immediately be shared to the world. |
| Computation | Notebook runs on a single instance, the instance needs to be configured, or accessed by a specific vendor, creating lock-in | Metapages run in the browser, but the compute runs on any computer or cluster, and each cell connects independently. Compute is abstracted away from the workflow |
| Search | There is no global index of searchable notebooks | Metapages includes search-as-you-type of all workflows, and components |
| AI | Notebooks have no specific AI integration | AI is directly integrating into creating code, so you don’t have to copy/paste, and all the code and data context is there automatically. |
| Durability | Notebooks can be persisted to github, but if they do not have an associated docker image defined, setup can be time-consuming. | Metapages are designed to be durable: the core runs in the browser, the most reliablely common compute environment, and all other compute runs in docker containers. We want them to run automatically in 50 years time |
| Collaboration | None | Real-time collaboration is built in |
Are metapages always a replacement for jupyter notebooks?
No. Metapages are closer to applications, or workflows, but they are not notebooks.
Metapages:
- are not linear (although they can be)
- are not built to present lots of text with some visualization, rather the opposite: visualization first, text optional
- are easily embeddable, and able to embed other tools
- currently have less integration with tools like debuggers
There will always be times when a notebook interface is more appropriate.
A example embedded metapage
Here is a very basic simple example of what you would also do in a jupyter notebook (run some code and visualize). Unlike a notebook, it runs in the browser without needing to spin up a specific compute instance, and (unlike a jupyter notebook) you can immediately copy, edit, share.
So take this, run it, and run with it. Once you open and clone it, it’s yours forever.