FAIR principles apply to data- what about compute

It’s one thing to have access to data, but it’s another thing to have code and also a reliable, reproducible way to run the code that operates on the data. In other words, it’s not enough to just serve data, we also need principles around HOW we create compute environments that process the data.
Data often doesn’t live on it’s own, it often requires extra tooling. For example, The Protein Data Bank https://www.rcsb.org/: it serves various protein structures and complexes, but also has multiple ways to display and interact with the 3D structures:
Simply having a database serving files is not enough. Researchers need tools integrated with with data to be able to view, summarize, search, etc.
Towards principles for FAIR-aligned computation
The FAIR principles are mostly about data, and accessing data. What’s missing is computation, or specifically, how the data is processed.
Ideally given some definition, a user can automatically reproduce and use a compute environment and run some code in that environment, operating on (FAIR 😀) data.
Since this is compute not data, the principles are overlapping, yet different:
Findable
This property is not as important as for data, because compute environments are inherently ephemeral. The underlying libraries and code to build the environments must be accessible.
Accessible
Code and tools to build and run the compute environments must be accessible.
- A1 The metadata describing how to build the environment must suffice for the majority of tools and systems used to run the environments.
- A2 The tools used to build the environment must be open, free, and universally implementable (e.g., Git, DockerHub, OCI registries).
- A3. Metadata remains accessible even if the code or environment is deprecated, providing references to alternative implementations or archived versions.
- A4. Where possible, compute environments are not prohibitive in resources to build unless specifically requirements dictate that necessity.
Interoperable
Code and compute environments should work across platforms and integrate seamlessly into workflows.
- I1. The compute environments described should be machine readable, and convertible into compatible platforms (e.g. docker and podman)
- I2. Code running in an environment build by one platform should run the same as an environment built with a different platform.
Reusable
Code and compute environments should be designed to be replicable and adaptable for future research.
- R1. A compute environment running some code can be used for running different, but compatible code. Where possible, environments can be re-used for efficiency.
The metapage platform solution
The metapage organization and platform is guided by FAIR principles, and we have developed an open source platform and API for representing docker containers and code as URLs:
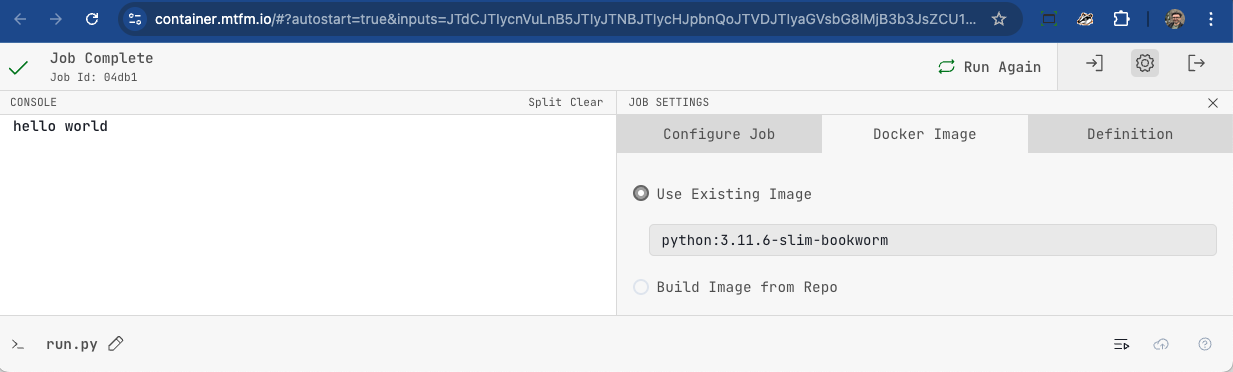
We like URLs encoding state here!
The URL encodes the full definition of:
- The
Dockerfile, or docker image - Optionally a git repository for building the docker image
- Optionally scripts to mount into the container at runtime
We provide a worker agent the user runs on their own computer or cluster or workstation. The worker takes the docker image definition, and builds the image, then runs the code+data in the container environment. This browser client is actually a component, and can be connected to other browser components to exchange data.
For a complete example showing a docker container running a ML workflow and producing visual output: https://metapage.io/dion/Python-ML-Workflow-385b95ab9cb04fa7a76df627b2bde668
User experience
As long as there is compute resources attached, users then do not have to manually install anything, or worry about their host system: the definition defined in the URL contains everything needed to reproduce the compute environment, and connectable from the browser.
Users can then take existing compute environments, complete with code, and directly modify, copy, and share these environments, directly as you would any other URL, or via our index of components
How it works
See here for detailed instructions
We provide an open and open-source compute queue API layer, where any user can create their own secure queue, connect their computer, and run docker containers and code all defined in a single URL.
The URL contains the Dockerfile definition, or a publicly accessible docker image, optionally code, optionally a github repository to build from.
This way, the mechanism to build a reproducible compute environment is simply a URL, where users simply add their own commodity compute resources (their laptop, workstation, cluster, almost anything that can run docker containers).
If the user wanted to run their own complete system that is different, they can, because the definition of the compute environment is encoded into the URL, thus available for all.